Обеспечение доступности сервиса для клиентов является важной задачей ИТ. Обеспечить её можно на разных уровнях:
- На уровне приложений;
- На уровне виртуальной машины (ВМ);
- На уровне СХД.
Далее мы рассмотрим сценарии использования каждого из них.
1. ОТКАЗОУСТОЙЧИВОСТЬ НА УРОВНЕ ПРИЛОЖЕНИЙ
Обеспечивается за счет избыточного количества компьютеров в группе (узлов или нод в кластере), объединенных каналами связи и представляемых конечному пользователю в виде единичного сервиса, называемого кластером. Вопрос заключается только в размещении этих нод. Можно разместить их в одном ЦОДе и решить проблемы, связанные с необходимостью проведения технологического обслуживания и с техническим отказом одного из узлов, переводя активную ноду с одного хоста на другой.
А можно подойти более глобально и разместить их в разных дата-центрах, тем самым значительно уменьшая риски и увеличивая количество факторов, от которых защищена система (СХД, гипервизоры, каналы связи, географическая распределенность). В инфраструктуре VMware vCloud Director это обеспечивается путем подключения к организации дополнительного виртуального дата-центра. После чего в панели управления облаком становится доступна возможность выбора VDC. 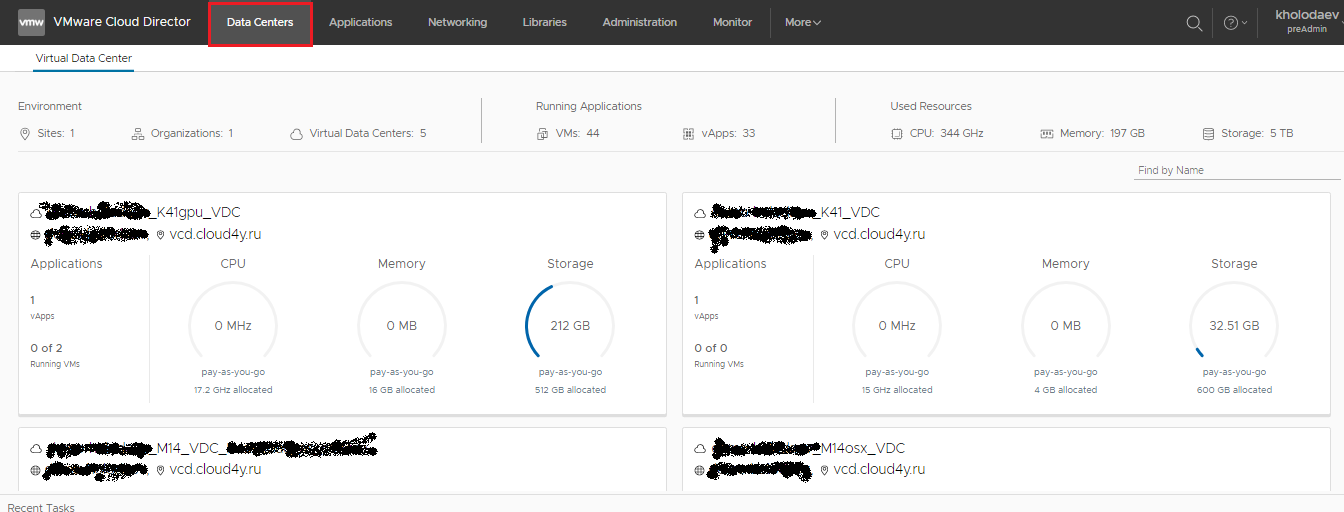
Каждый VDC является независимым. В нем вы можете создавать свои vApp, независимые сети, VMware vShield Edge и другие объекты виртуальной инфраструктуры. Для этого выберите в панели нужный VDC, находясь на вкладке Datacenters. Выбранный VDC показывается вверху экрана.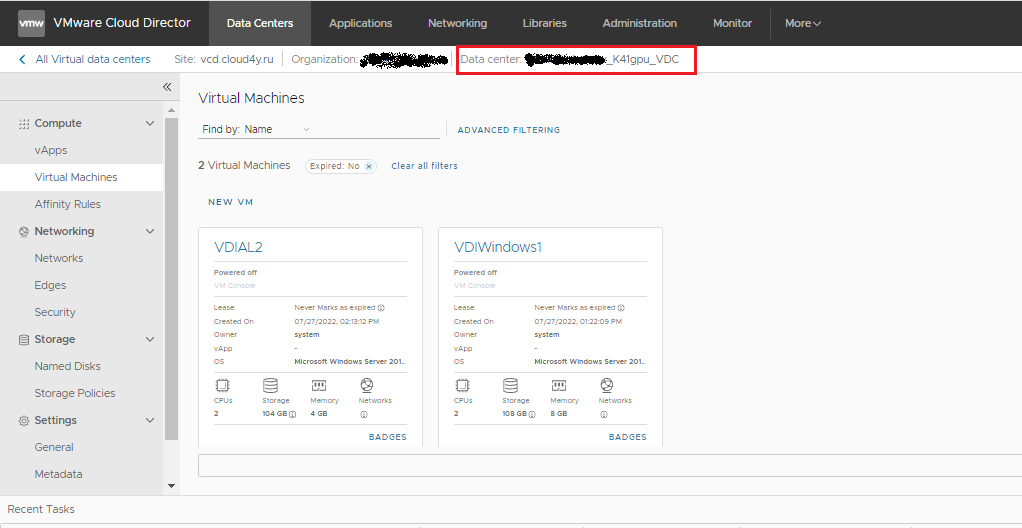
Создавая новый vApp, вы всегда можете предварительно выбрать нужный VDC, в котором вы хотите разместить свои виртуальные машины. 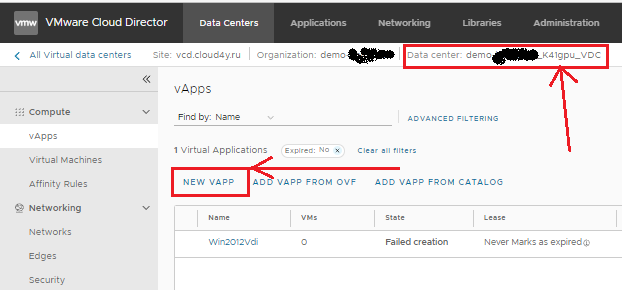
В панели vCloud Diector определить размещение вашего vApp помогает заголовок окна. 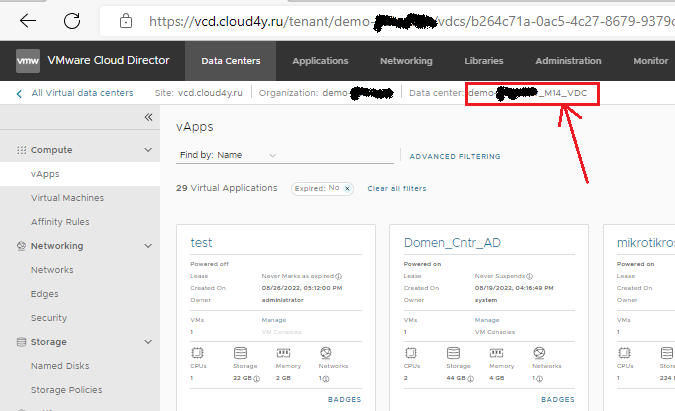
Создавая в различных ЦОДах свои vApp-ы и размещая там ноды виртуальных машины, вы на уровне приложений обеспечиваете отказоустойчивость множества сервисов, например, это решение применимо к:
- Microsoft Exchange, используя кластер DAG (Database Availability Group)
- Microsoft Active Directory, используя механизм репликации между контроллерами домена
- DFS
- Microsoft SQL Server, с использованием технологии AlwaysOn (начиная с MS SQL Server 2012) можно использовать вторичные реплики, при этом возможна репликация как синхронная (медленная, без потери данных), так и асинхронная (быстрее, с возможной потерей данных). Более подробно смотрите: https://docs.microsoft.com/ru-ru/sql/database-engine/availability-groups/windows/overview-of-always-on-availability-groups-sql-server?view=sql-server-2017
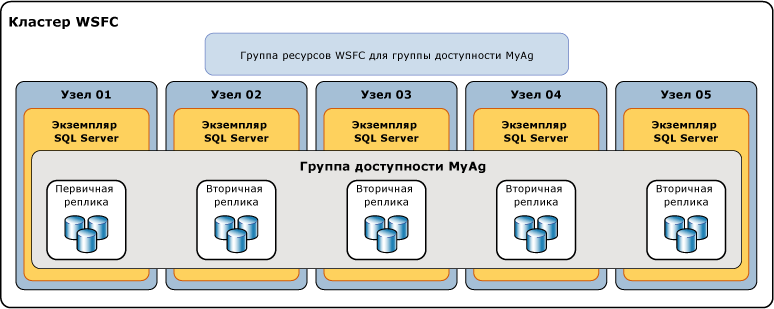
- И другим сервисам.
Сетевая связанность между виртуальными машинами, размещенными в разных ЦОДах может быть обеспечена:
- Путем проброса VLAN между ЦОДами, через подключения дополнительной услуги от Cloud4Y. Это позволяет использовать единую частную сеть (серые адреса) между всеми ВМ.
- Через публичные сети (интернет), путем создания дополнительного VMware vShield Edge с белым IP-адресом во втором ЦОДе и связи по публичным IP адресам, или при настройке VPN канала между EDGE-ами по серым адресам. При этом в разных ЦОДах серые подсети должны быть разными.
Обе эти возможности можно комбинировать. С одной стороны, вы позволите серверам общаться напрямую без VPN. А с другой стороны, обеспечите две публичные точки (белые IP-адреса) в разных ЦОДах для подключения ваших пользователей и предоставите сервис с высоким уровнем доступности.
2. ОТКАЗОУСТОЙЧИВОСТЬ НА УРОВНЕ ВИРТУАЛЬНОЙ МАШИНЫ
Решая стратегическую задачу по обеспечению высокой доступности виртуальной машины, предлагаем воспользоваться возможностями Veeam Backup & Replication. 
Данная технология, используя реплики, позволяет создавать готовые к запуску копии виртуальной машины в другом ЦОДе. Репликация Veeam ускоряет послеаварийное восстановление, предотвращает потерю данных и обеспечивает непрерывность бизнес-процессов.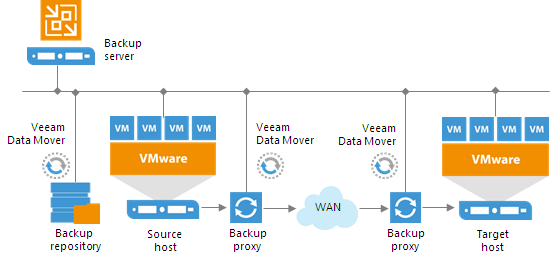
Если исходная машина в одном из ЦОДов по какой-то причине перестанет работать, вы сможете быстро переключиться на реплику и восстановить критичные для бизнеса службы и приложения с минимальным простоем в другом ЦОДе. Для пользователей это произойдет быстро, и они смогу продолжить свою работу, в то время как ИТ-персонал займётся устранением неполадок в "проблемном" ЦОДе. 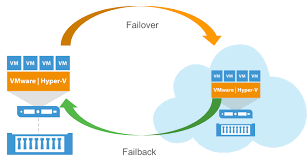
Создание реплики виртуальной машины осуществляется путем создания заданий на репликацию с определенной периодичностью. Во время первой сессии задания репликации Veeam Backup & Replication копирует образ виртуальной машины целиком и регистрирует копию виртуальной машины на целевом хосте ESX(i). При последующих сессиях задания Veeam Backup & Replication копирует только измененные блоки данных виртуальной машины относительно последней сессии (инкрементальные изменения) и создает новую точку восстановления для реплики виртуальной машины. 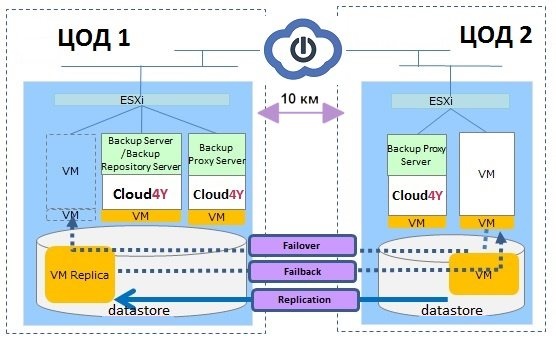
Используя эту точку восстановления, вы можете «откатить» виртуальную машину до нужного состояния. Мы рекомендуем поддерживать несколько точек восстановления, чтобы гарантировать работоспособность реплики. В случае, если последняя точка восстановления окажется нерабочей, можно будет использовать более раннюю точку.
После устранения проблемы в одном из ЦОДов можно переключиться с реплики обратно на исходную виртуальную машину или продолжать использовать реплику в качестве рабочей ВМ.
3. ОТКАЗОУСТОЙЧИВОСТЬ НА УРОВНЕ СХД
Для заказчиков, перед которыми стоят специфические задачи по катастрофоустойчивости, предлагаем решение SyncCluster, обеспечениющее высокую отказоустойчивость и доступность сервисов.
Cloud4Y разработал новое решение на российском рынке облачных услуг — SyncCluster c SLA 99.99%. SyncCluster является уникальной услугой, которая совмещает в себе массив на основе кластеров с синхронным зеркалированием. 
В Москве реализована система хранения, в которой одна половина находится в одном дата-центре уровня Tier 3, а вторая на расстоянии 10 км в другом дата-центре уровня Tier3, при этом обе половины работают синхронно, как единая структура. Этот подход гарантирует, что данные запишутся и в одну и в другую СХД. В случае любого сбоя в одном из дата-центров (отказа питания, выхода из строя любой части системы хранения, выхода из строя контролеров, множества дисков в одной дисковой группе в короткий промежуток времени, каналов связи между дата-центрами) ваши данные останутся доступны, (RPO=0 (Recovery point objective - допустимая потеря данных), RTO=10 минут (Recovery time objective - допустимое время восстановления данных)), т. е. не теряется ни одна транзакция.
Если в предыдущем решении репликация велась на уровне виртуальной машины и с определенными периодами, то здесь идет синхронная репликация на уровне СХД постоянно, это позволяет избежать излишней нагрузки на серверы, обеспечить максимальный уровень SLA 99,99% и сохранить данные. Указанное решение особенно подходит для программного обеспечения, которые не поддерживают репликацию на уровне приложений.
SyncCluster от Cloud4Y — это экономически эффективное решение, которое обеспечивает постоянную доступность сервисов и данных для компаний, в которых непрерывность бизнеса является критичной. Мы предлагаем MetroCluster в формате услуги с помесячной оплатой, это позволит нашим клиентам снизить капитальные затраты на покупку оборудования и его техническое содержание.
СРАВНЕНИЕ РЕШЕНИЙ
Подойти к выбору необходимого уровня сервиса для вашей ИТ-инфраструктуры с учетом факторов риска и требований к реализации вам поможет таблица:
|
|
ПРИ РАЗМЕЩЕНИЕ ИТ-ИНРАСТРУКТУРЫ В ДВУХ ЦОДах с защитой на уровне: |
ПРИ РАЗМЕЩЕНИЕ ИТ-ИНРАСТРУКТУРЫ В ОДНОМ ЦОДе |
||
|
Приложений |
Виртуальной машины |
СХД |
||
|
|
||||
|
Отключение основного, резервного электропитания и отказ ДГУ в одном ЦОДе |
ЕСТЬ |
ЕСТЬ |
ЕСТЬ |
НЕТ |
|
Отказ основной и резервной системы кондиционирования |
ЕСТЬ |
ЕСТЬ |
ЕСТЬ |
НЕТ |
|
Пожар в одном ЦОДе |
ЕСТЬ |
ЕСТЬ |
ЕСТЬ |
НЕТ |
|
Техногенные катаклизмы |
ЕСТЬ |
ЕСТЬ |
ЕСТЬ |
НЕТ |
|
Природные катаклизмы |
НЕТ |
НЕТ |
ЕСТЬ |
НЕТ |
|
Проведение в одном дата-центре следственных мероприятий |
ЕСТЬ |
ЕСТЬ |
ЕСТЬ |
НЕТ |
|
Множественный отказ (более 4-х) каналов связи в одном ЦОД-е в короткий промежуток времени |
ЕСТЬ |
ЕСТЬ |
ЕСТЬ |
НЕТ |
|
Множественный отказ коммутационного оборудования |
ЕСТЬ |
ЕСТЬ |
ЕСТЬ |
НЕТ |
|
Полный или частичный отказ СХД |
ЕСТЬ |
ЕСТЬ |
ЕСТЬ |
НЕТ |
|
Полный или частичный отказ одного гипервизора |
ЕСТЬ |
ЕСТЬ |
ЕСТЬ |
ЕСТЬ |
|
Отказ сервера vCenter |
ЕСТЬ |
ЕСТЬ |
ЕСТЬ |
НЕТ |
|
|
||||
|
Необходима поддержка со стороны прикладного ПО |
ДА |
НЕТ |
ДА / НЕТ |
НЕТ |
|
Потеря данных (RPO) |
В зависимости от приложения – ЧАСТИЧНАЯ / ОТСУТСТВУЕТ |
ЧАСТИЧНАЯ, до последней рабочей реплики |
ОТСУТСТВУЕТ |
ЧАСТИЧНАЯ, до последнего бэкапа |
|
Время восстановления (RTO) |
В течение нескольких минут |
В течение часа |
В течение нескольких минут |
В течение нескольких часов, в зависимости от размера данных |
|
Стоимость решения |
Низкая |
Средняя |
Высокая |
Минимальная |
* - Более точную стоимость по каждому решению вы можете получить у вашего персонального менеджера
